深入剖析Vulkan交换链相关的同步机制
Vulkan中的呈现模式和交换链设置一直是很重要的话题,呈现过程中,涉及到大量Host(CPU)和Device(GPU)之间的同步处理,这部分相对复杂,本文将深入其中,探究怎样正确处理这一过程。
交换链
交换链是连接渲染过程与呈现过程的桥梁,GPU渲染好一张图像后,需要提交给交换链来显示到显示器上。渲染和呈现的操作都是在GPU上完成的,一般来说渲染在GraphicsQueue上完成,而呈现在PresentQueue上完成。CPU做的是在主循环中,向交换链寻求一张空闲的图像,并录制命令提交给GPU,指示GPU在这张图像上进行绘制,绘制完成后紧接着呈现。由于CPU天然是串行的,GPU天然是并行的,因此两者之间的沟通必须通过各种各样的同步方式来严格限制执行顺序。
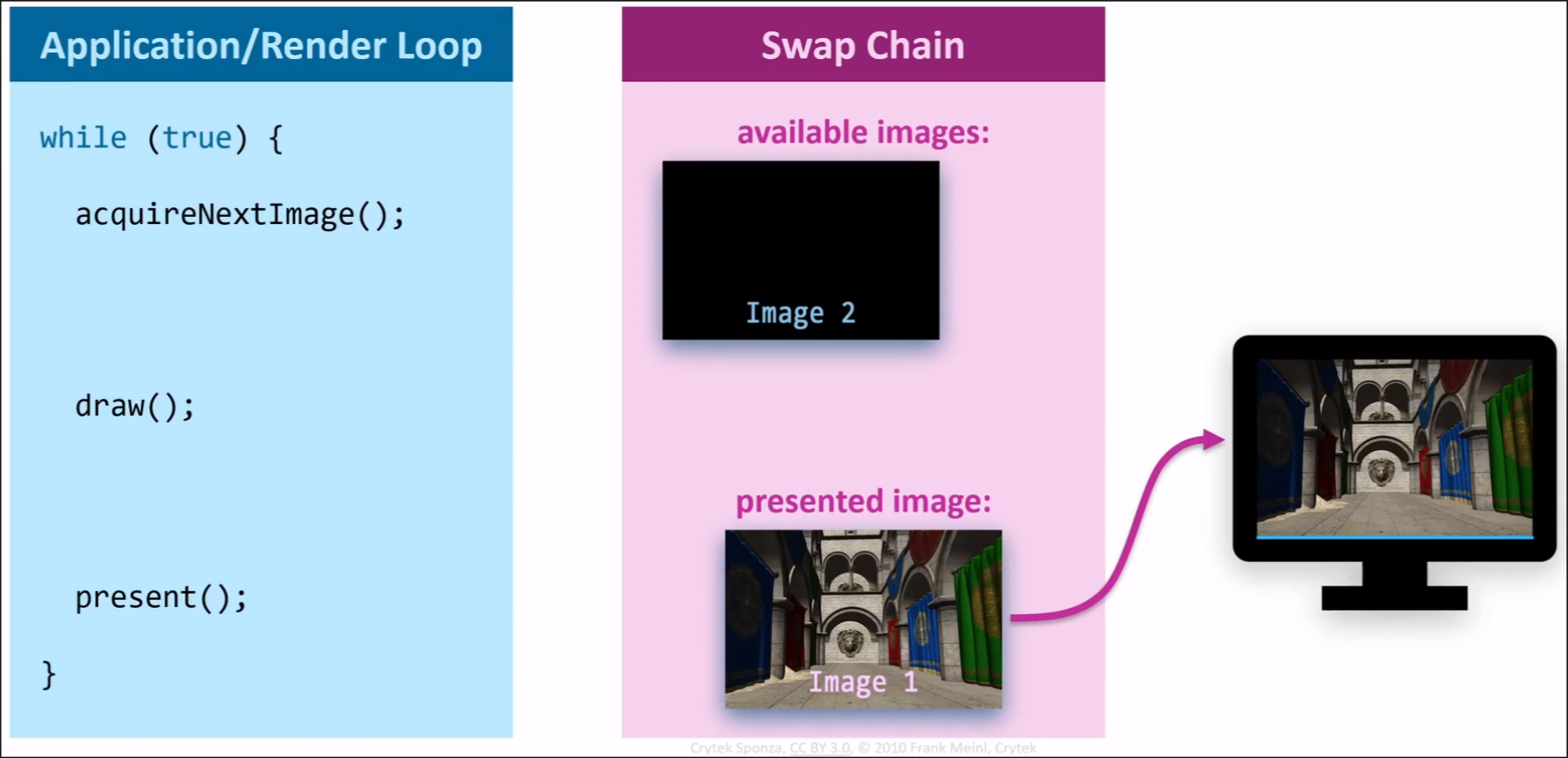
交换链内部管理一组图像,数量至少为2,确保一张用于显示时,另一张可用于渲染;但通常图像数量设为3,确保在启用垂直同步时,一张用于显示,一张在等待显示时,第三张还可以用于渲染,从而避免GPU阻塞CPU的情况。在Vulkan中,这一组图像实际上是 vk::Image(由交换链管理)+vk::ImageView+vk::FrameBuffer,CPU通过acquireNextImage得到vk::Image的索引后,在绘制命令中指定这张Image对应的FrameBuffer,而在呈现命令中,则是直接用索引告诉GPU要将对应的Image呈现到显示器上。
呈现模式
呈现是GPU将图像数据传输给显示器,进行从左往右、从上到下的显示过程。一般的显示器有一个显示频率,也就是垂直更新频率,如60Hz,表明显示一张图像的时间小于16.6ms,这期间,扫描线从上而下移动,显示读取到的数据。当扫描线返回顶部时,我们称这个事件为“垂直空白”(Vertical Blank),在现代显示器,这个事件用于指示一个时间点,该时间点可以安全地交换正在传输到显示器的图像。
由于渲染和呈现是两个独立的过程,因此很有可能有多张图像通过呈现命令提交给GPU,但是GPU来不及显示,这时需要交换链的呈现模式(Presentaion Mode)来控制待呈现图像的管理。本质上,呈现模式就是在设置 Vertical Blank 如何指示图像的传输。
Vulkan中有四种呈现模式,分别是Immediate, FIFO, FIFO Relaxed, Mailbox。
-
Immediate模式下,每当有新的待呈现图像提交给交换链时,交换链会立即丢弃当前正在传输的图像,转而使用新的图像继续传输,也就是完全不考虑Vertical Blank事件,该模式会导致画面撕裂的问题(Tearing)。
-
FIFO,即First In First Out,顾名思义,交换链会维护一个队列,新的待呈现图像加入队尾,每次出现Vertical Blank时,从队头取出一张要呈现的图像,并在下次Vertical Blank之前始终传输该图像的数据,该模式即最经典的垂直同步模式,也是Vulkan规范规定的唯一一个所有驱动都要支持的呈现模式,可以完全解决画面撕裂的问题,但是会导致一定延迟,因为每次从队列中取出的图像经过排队,已经不是最新绘制好的图像了。
-
FIFO Relaxed,是上一种模式的改进,用于在特定情况下减少延迟。特定情况是指,当渲染过程特别慢时,在一次Vertical Blank发生后,队列中可能还没有待呈现的图像,在下一次Vertical Blank之前,如果有图像进入队列,则立刻不再等待Vertical Blank,直接将该图像进行传输,当然这个传输就不是从头到尾的了,扫描线已经在中间某处,只能显示部分图像。因此该模式还是会有轻微的画面撕裂问题,但是减少了延迟。
,也就是完全不考虑Vertical Blank事件,该模式会导致画面撕裂的问题(Tearing)。 -
Mailbox模式中,交换链不再维护队列,而是维护一个“邮箱”,只能同时容纳至多一张待呈现的图像,当有新的待呈现图像提交时,邮箱会存储这张新图像,丢弃原来存的图像(若有的话),在Vertical Blank时,取出邮箱内的图像进行传输。该模式也是完全解决画面撕裂的问题的,而其当渲染速度很快时,Mailbox模式使得延迟降到最小。但是也导致有部分渲染的图像根本没有呈现就被丢弃了。
总结各模式的特点:
- Immediate模式完全无延迟,但是画面撕裂。
- FIFO完全无画面撕裂,但有相对固定的延迟。
- FIFO Relaxed用于在渲染速度低于刷新率的情况下,通过轻微画面撕裂的代价,减少延迟。
- Mailbox用于在渲染速度高于刷新率的情况下,完全无画面撕裂且延迟最小。
因此在高性能游戏中,Mailbox通常是最优选择。
同步原语
同步原语(Synchronization Primitives)是Vulkan中用于控制Host和Device各种操作的顺序的对象。Vulkan中有五种常见的同步原语:信号量(Semaphore),围栏(Fence),管线屏障(Pipeline Barrier),子通道依赖(Subpass Dependencies),以及事件(Event)。我们关注其中两者:Semaphore和Fence。
Semaphore有2种,Binary Semaphore和Timeline Semaphore,这里我们只讨论Binary Semaphore。这种Semaphore用于Device内部,队列之间的同步。它只有两种状态,signaled和unsignaled,向队列提交命令时,可以传入一个unsignaled的Semaphore,当GPU完成该命令的工作后,会激活这个Semaphore,其状态变为signaled;同时,向队列提交命令时,还可以传入一个要等待的Semaphore,当该Semaphore激活时,GPU会“消费”这个Semaphore(即将其变回unsignaled),再开始命令对应的工作。通过这种方式,我们可以管理Device内各工作的执行顺序。
Fence用于Host和Device之间的同步,它也是signaled和unsignaled两个状态。向队列提交命令时,可以传入一个Fence,在Device完成该命令的工作后,会激活这个Fence。可以在Host等待这个Fence,这一过程阻塞CPU,当Fence激活时,等待才会结束,这里与Semaphore不同的是,等待后Fence不会自动重置为unsignaled状态,需要手动重置。Fence可以让Host等待Device完成指定的工作,从而控制主循环的频率。
这里我们要控制Host、Device的GraphicsQueue和PresentQueue之间的同步关系,用到的各个同步原语作用如下:
- 1个Fence,用于CPU主循环中等待GPU完成工作。
- 1个Semaphore,用于确保PresentQueue通过
AcquireNextImageKHR返回的图像可用之后,再让GraphicsQueue开始渲染。 - 另1个Semaphore,用于确保GraphicsQueue渲染完成之后再开始呈现。
多帧并行渲染
在CPU主循环中,主要的操作是以下三步:
- 从交换链获取可用图像
- 记录并提交命令缓冲区,指示GPU将绘制到该图像上
- 呈现交换链图像
由于交换链有多张图像,这是不是意味着我们已经实现了多帧并行渲染了呢?并非。因为每次循环要确保,CPU录制的命令缓冲,以及提交命令用到的同步原语不能发生数据竞争。如果每次在循环内创建需要的命令缓冲与同步原语,理论上可行,但实际上几乎不会采取,一是性能开销巨大,二是不好控制同步原语的销毁时机:在循环内销毁时,可能GPU还在用;如果等待Fence再销毁,那就又退化到了串行的效率。
因此,我们需要维护多组命令缓冲与同步原语,这种方法称为"Frame In Flight"。其思路是维护一个环形数组(Ring Buffer),每个元素表示一帧内所需要的命令缓冲与同步原语。循环内滚动使用各个元素。这个数组的大小表示CPU能并行录制的帧数,一般来说,这个帧数交换链中的图像数,可以这么理解:每录制一帧,一定对应交换链中的一个图像;但交换链中的图像不止用于录制,还可能在用于呈现以及待呈现。一般来说,交换链图像数为3,并行录制的帧数为2就行。
使用这种方法,主循环中的操作就要在第2步前某处加上一步:等待当前数组元素中的命令缓冲与同步原语都空闲。这时主循环中可能发生阻塞的地方有两处:一是这里等待同步原语,由并行录制帧数影响;二是从交换链获取可用图像,要等待有空闲图像返回为止,由交换链图像数影响。可见二者共同控制了主循环的帧率。
一个常见错误
虽然理论如此,但是在Vulkan的实现中,实际上会遇到一个问题的,部分教程忽略了这个问题,导致验证层报错。问题在于:我们要如何等待所有同步原语,确保它们都已空闲?
在Vulkan1.0中,呈现命令presentKHR是不支持传入Fence的,我们只能在提交绘制命令时传入Fence,并在每帧开头等待,这样导致的问题是:等待结束之后,只是保证了使用这组同步原语的上一帧的渲染已经结束,但是不能保证那帧的呈现操作已经开始。因此用于渲染结束激活、呈现之前等待的那个Semaphore可能仍被PresentQueue占用。一项工作要等待的Semaphore,在工作真正开始时才被消费,变回unsignaled,这时该Semaphore不再被占用。
因此,部分教程给出了类似如下的错误代码(取自Vulkan官方文档):
1 | // !! BAD CODE WARNING !! |
在部分设备上,这样的代码不会导致太大问题,甚至不会有验证层报错,但是笔者实践中发现,如果涉及到交换链重建,则还是可能有验证层报错。
解决方案
方案一
官方文档中给出了一种十分巧妙的解决方法,将有占用风险的submit_semaphore,不再作为Frames In Flight每帧一个的资源,而是对应交换量中的图像每张一个。每次提交命令中绑定的Semaphore是该次得到的交换链图像对应索引的submit_semaphore。
这样为什么能解决问题呢?因为AcquireNextImageKHR返回的图像,Vulkan规范 确保“上次 present 对该 image 已完成,图像不再被显示系统使用”,这也保证了对应的Semaphore一定被消费了,故可以安全复用。
Acquiring the image index from
vkAcquireNextImageKHRand then waiting on its semaphore or fence guarantees that the previous presentation operation that used the just-acquired image index has completed, which includes the wait onVkPresentInfoKHR::pWaitSemaphores, so the corresponding semaphores can be reused.
由此得到的正确代码如下(同样取自Vulkan官方文档):
1 | // !! GOOD CODE EXAMPLE !! |
方案二
Vulkan文档中还提到另一个更彻底的解决方案,即使用扩展VK_EXT_swapchain_maintenance1。该扩展允许呈现命令传入Fence,当呈现结束之后,Fence激活,在循环中我们只要等待这个Fence就可以了,之前在绘制命令中提交的Fence可以不用了。等待呈现完成了,那上一次Present用的Semaphore必然已经消费了。但是规范中没有给出完整的代码,这里给出我自己的实现。
要启用该扩展,我们要在Instance层面启用VK_EXT_surface_maintenance1和VK_KHR_get_surface_capabilities2扩展,然后在Device层面启用
VK_EXT_swapchain_maintenance1。
其中VK_EXT_swapchain_maintenance1的启用需要使用结构链,以下为vulkan-hpp的写法:
1 | vk::StructureChain<vk::DeviceCreateInfo, vk::PhysicalDeviceSwapchainMaintenance1FeaturesEXT> deviceChain; |
主循环中的代码大致如下:
1 | auto& frame = framesInFlight[curFrame]; |
参考资料: